FlexNER (Project Tutorial)
+++ updating +++
![]()
FlexNER is a toolkit of neural NER models designed to accelerate ML research. This version of the tutorial requires TensorFlow >=1.4. It is a preview. The detailed descriptions are still in the making.
Contents
Basics
Installation
usage: train.py [-h] [-a ALGORITHM] [-ag AUGMENT] [-m MODE]
[-mp MODEL_PATH] [-g1 GRADIENT_STOP_NET1]
[-g2 GRADIENT_STOP_NET2] [-g3 GRADIENT_STOP_NET3]
[-g4 GRADIENT_STOP_NET4] [-r1 MASK_NET1]
[-r2 MASK_NET2] [-r3 MASK_NET3] [-r4 MASK_NET4]
This list provides the options to control the runing status.
optional arguments:
-h, --help show this help message and exit
-a ALGORITHM, --algorithm ALGORITHM
Select an algorithm for the model
-ag AUGMENT, --augment AUGMENT
1:True 0:False
-m MODE, --mode MODE Select training model. train, restore, tune
-mp MODEL_PATH, --model_path MODEL_PATH
Select the model path
-g1 GRADIENT_STOP_NET1, --gradient_stop_net1 GRADIENT_STOP_NET1
1:True 0:False
-g2 GRADIENT_STOP_NET2, --gradient_stop_net2 GRADIENT_STOP_NET2
1:True 0:False
-r1 MASK_NET1, --mask_net1 MASK_NET1
1:True 0:False
-r2 MASK_NET2, --mask_net2 MASK_NET2
1:True 0:False
For the Baseline model
bash run_n1.sh
For the Joint training
python run_n1.sh with -g1=0 -r1=0 -g2=0 -r2=0
For the separated training
(1) bash run_n1.sh
(2) bash run_n2.sh
(3) bash run_n1.sh with -g1=1 -r1=0 -g2=1 -r2=0
Addition
Multi-lateral Network
3 steps to build a simple multi-lateral NER architecture.
class Bi_Stacka(Bi_NER):
# initialize the constructor
...
# define a arch.
def mix(self):
# 1. add the embeddings
self.base_embed=self.embedding_layer_base()
# 2. define your arch.
encode1=self.mix_stacka('net1')
encode2=self.mix_stacka('net2')
encode3=self.mix_stacka('net3')
# concatenate the vector
self.encode=tf.concat([encode1,encode2,encode3],axis=-1)
# additional process
...
# 3. add a crf layer
self.crf_layer()
Language Correlation
This framework can also be applied to multilingual research.
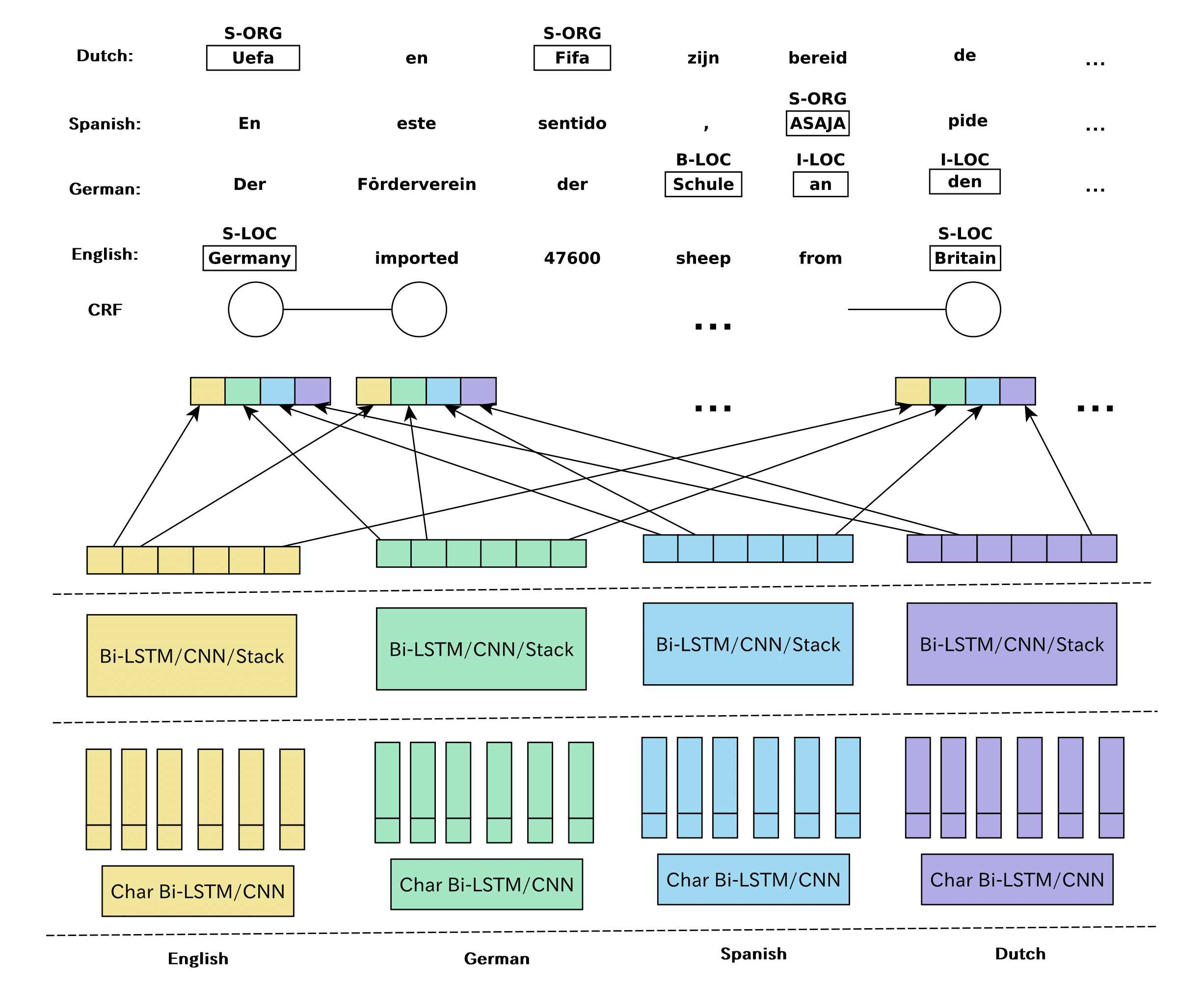
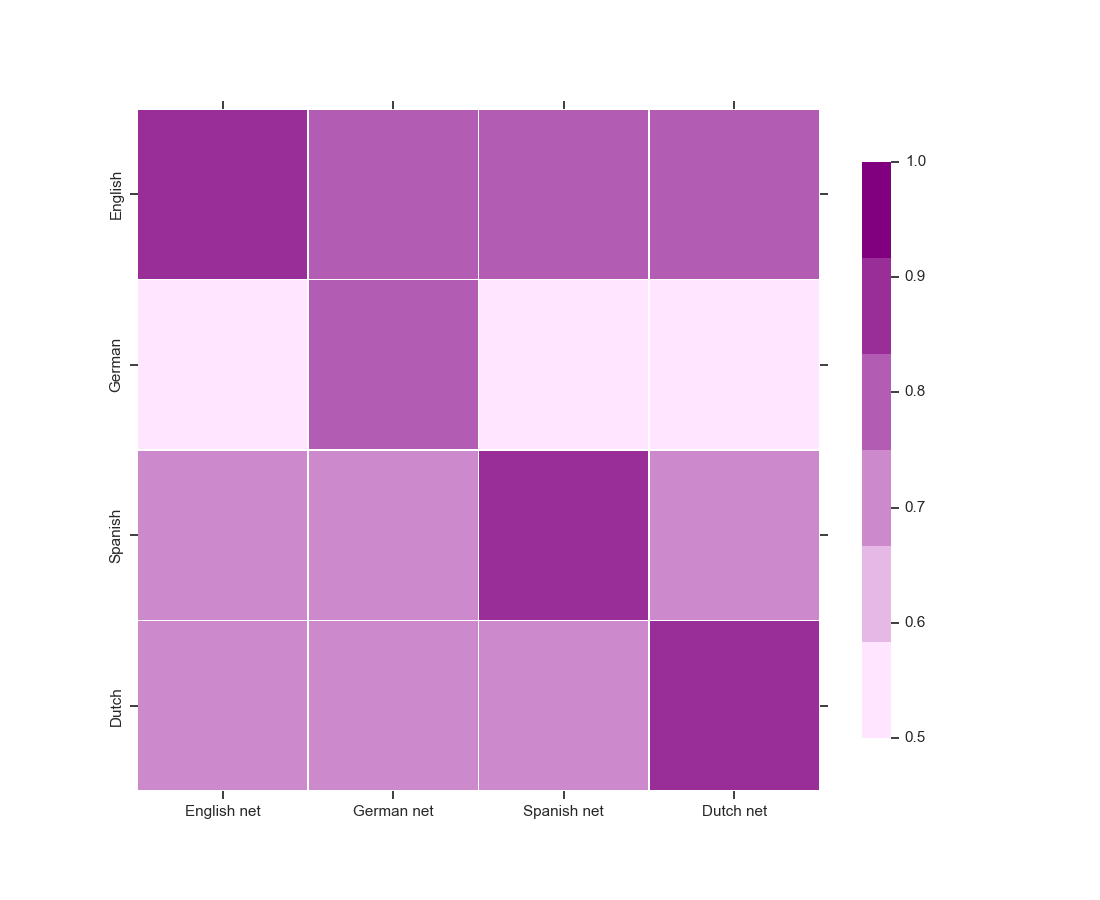
These sub-networks trained in other languages can also achieve certain performance in a new language (although not good enough), and based on this phenomenon we consider their micro F1 scores as a reflection of the correlation between languages, as shown below.
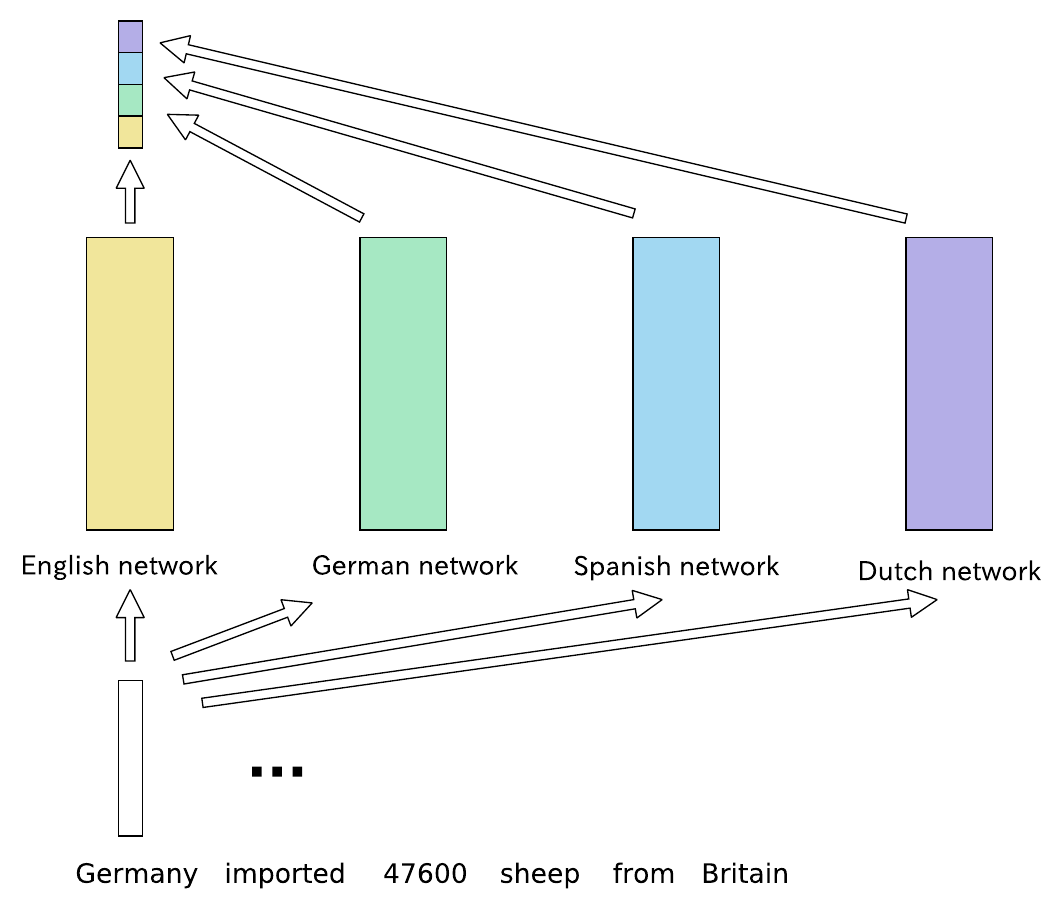
Language Interaction
These sub-networks can also be combined to asynchronously train different languages simultaneously, allowing them to work together to update the model. At this point, we need to use separate output layers for each language because their sequence lengths are different.
Suggested Datasets
- CoNLL-2003 English link
- CoNLL-2003 German link
- CoNLL-2002 Spanish link
- CoNLL-2002 Dutch link
- Chinese link
- NYT dataset link
- Biomedical domain link
The augmented data set can be 3-10 times the original training data.
Story of FlexNER
Some friends may want to know why you are doing this, and now we have stronger models. Because this framework has a story. At the very begining (2017-Sep), the idea of entity augmentation is a sort of simple because I only use shallow network blocks (i.e. LSTM layer and additive attention), so it naturally does not meet the requirements for publishing the paper. Besides, paper writing needs to be improved. I think I should introduce some more complicated mechanisms, so I tried several attentions, but the improvement is not obvious. I think there is a kind of context common sense, which is why I proposed this method. Context common sense is different from the KB common sense. This theory is not perfect enough, so it is naturally challenged in another proposal. I am just talking about it to generate more inspiration. This may include immature ideas, so this theory needs to be explored more before it is completed. Then, 2018-Nov, BERT completely beats this approach. I can not think of using the effective transformer blocks. (:(|)!!!
This story may answer the questions.
Updating…
- 2019-Mar-20, FlexNER v0.3, reconstructing the code
- 2018-Nov-03, FlexNER v0.3, support different languages ( tested on English, German, Spanish, Dutch) and biomedical domain
- 2018-Apr-05, Bi_NER v0.2, support easily customizing architecture and more attention mechanism
- 2017-Sep-10, Bi_NER v0.1, initial version, present NER data augmentation